TL;DR: Mastodon’s Sidekiq deferred execution jobs are the limiting factor for scaling federated traffic in a single-server or small cluster deployment. Sidekiq performance scales poorly under a single process model, and can be limited by database performance in a deployment of the default Dockerized configuration.
If you are an embattled instance admin, go here.
I recently moved to a well-established Mastodon (Hometown fork) server called weirder.earth, a wonderful community with several very dedicated moderators and longstanding links to other respected servers in the fediverse. Overall, it’s been lovely; the community is great, the Hometown fork has some nice ease-of-use features, and the moderators tend to squash spam and bigotry pretty quickly.
Then Elon Musk bought Twitter.
The Setup
Just as tens of thousands of people1 fled Twitter to join the fediverse, Weirder Earth had a storage migration pending. It did not go well, for reasons unrelated to this post, and the instance was down for several hours.
Normally, this would not be a problem; ActivityPub2, the protocol that powers Mastodon and other fediverse software, is very resilient to outages, and most implementations have plenty of built-in mechanisms like exponential backoff and so forth to get their neighbors up to date when they come back online. This particular outage, however, coincided with a huge amount of traffic, so when the server did come back online, there were many tens of thousands of messages waiting for it. Each of these messages necessitates a Sidekiq task which integrates it into the database, users’ timelines and notification lists, and so forth.
Sidekiq did not succeed in handling this load.
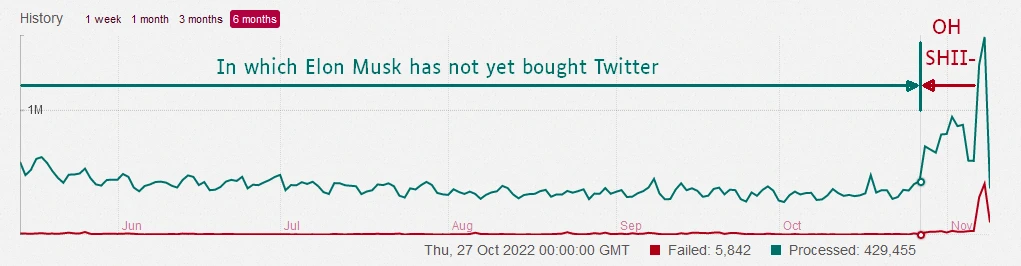 A screenshot from the Weirder Earth Sidekiq dashboard, showing processed and
failed jobs over time. Created and edited by Packbats.
A screenshot from the Weirder Earth Sidekiq dashboard, showing processed and
failed jobs over time. Created and edited by Packbats.
Users began to experience multi-hour delays in incoming federation, though outgoing federation was unaffected. To users of other instances, nothing was wrong; weirder.earth posts showed up within seconds, or about two minutes at the worst. Even to weirder.earth users, the web interface worked perfectly well; it’s just that there was little new content to populate it.
The Sidekiq queue grew and grew over time, eventually reaching a peak of over 200,000 queued jobs. In conversation with the admin of another instance of a roughly similar size, I learned that processing a 6-digit number of jobs is a day is only a fairly recent phenomenon. So, this was an issue.
The Cause
I became involved with this situation during the initial outage, helping with Docker problems, alongside another user, the Packbats,3 and another instance admin. As the Sidekiq queue grew and grew, myself and two of the instance’s admins looked into every possible cause, mostly sifting through documentation, since it was not an area of expertise for any of us.
It was immediately clear that at least part of the problem was Sidekiq’s inability to successfully use the 8GB of memory and 4 CPU cores available to the server; the RSS of the single Sidekiq process was around 350 MB, and the load factor was averaging around 3 – not even fully utilizing the 4 available cores.
So, we started increasing the number of workers available to Sidekiq.
This was done by increasing MAX_THREADS and passing the -c (“concurrency”)
argument to Sidekiq.
(We later learned that DB_POOL is more appropriate; see below.)
We increased first to 15, then to 25, and finally to 50, which is the
mythical “stable limit” of Sidekiq according to several StackOverflow posts.
It helped, but the queue depth was still growing, so we increased our database container’s max connections to 200 (by adding -c ‘max_connections = 200’ to the invocation in docker-compose.yml) and increased to 150 Sidekiq threads. Again, this helped, but overnight the queue continued to grow.
At this point, I realized that the bottleneck was not in Sidekiq anymore; individual jobs had gone from completing in seconds to tens of seconds and even sometimes over a minute. One of the instance admins pulled up PgHero and we realized that, indeed, the database was being incredibly conservative with memory. By default, it was using only 128MB for shared buffers, which is dramatically low on a server with 4GB of memory and a workload like Mastodon, where a huge volume of traffic is just fetching the same few posts and conversations over and over again. So, we increased that to the aggressive value of 2GB, and again saw an improvement in performance. Rather than growing, the queue was now stable, at 194,000 events and a latent time of about 14 hours.
We had conquered the first derivative.
The Solution
Ultimately, the real solution as a combination of three things:
- Increasing the memory available to the database for shared buffers
- Increasing the number of threads available to Sidekiq
(and, accordingly, the database connection pool size and maximum number of
connections via
DB_POOLandmax_connections) - Splitting Sidekiq’s queues off into their own processes.
See, Mastodon uses 5 Sidekiq queues: default, push, pull, mailers, and
scheduler.
For us, push was conquered early on,
and mailers and scheduler were never an issue,
having very low volume.
pull, for getting incoming federation events, and default, for building
notifications and timelines, were the real trouble.
So, we split them into their own Sidekiq processes.
We had gone up to 200 max_connections and a concurrency of 150, so I
guesstimated that the following split would work well:
- a single container/process for the
push,mailers, andschedulerqueues with 25 threads - a container/process each for
pullanddefaultwith 60 threads each
This worked great for pull. We went from holding steady to dropping about 500 events every
minute, and rapidly cleared the entire pull queue – but the default queue was
still holding on. 4
This was harder to diagnose, but eventually we realized that the Sidekiq
instance working on the default queue wasn’t at its full potential.
Looking at the PgHero connection status dashboard,
we could see that many of our 200 connections were held by inactive or
low-activity Sidekiq processes with names like sidekiq 6.2.1 mastodon [0 of 25 busy] while the active ones were only holding a few connections.
But that should be okay, right? 60 + 60 + 25 is much less than 200,
so there should be plenty of connections to go around.
As it turned out, Puma was also configured to use lots of database connections
(MAX_THREADS = 150), so it was hogging many that it didn’t need.
We sorted that out, refined our Postgres config to allow even more connections,
split the Sidekiq processes up even more,
with fallbacks and various different ordered combinations of queues.
We all went to sleep and woke up to an empty queue!
We’ve been experimenting and optimizing since, but the server has been coping with the load handily since.
Lessons Learned
The default Mastodon configuration is broken. It’s fine for a tiny instance on a tiny server, but once you start to grow, you must scale it up. Here’s what we did:
Increase Your Database’s Resources
By default, especially in the default Docker setup, Postgres is not using any appreciable percentage of your memory. I suggest using PgTune, choosing an “online transaction processing” or OLTP workload, setting about half of your server’s memory, and applying whatever it says.
In Docker, it’s easiest to apply this through adding -c "option=value"
arguments to the invocation in docker-compose.yml;
this can also work if you’re invoking Postgres through a SystemD unit.
Or, you can use postgresql.conf. Don’t forget to restart the database.
Split Your Sidekiq Queues
Sidekiq can scale to as many as hundreds of threads on a single process, but using multiple processes is much more efficient. Before increasing concurrency (that’s the next step!), split out the queues into different processes.
All the queues in Mastodon can be split among multiple processes,
except for scheduler, which must only ever be on a single process.
I recommend having a single Sidekiq process each for the mailers and scheduler
queues, and then processes that prioritize pull, push, and default.
You can specify queues with the -q option in docker-compose.yml or your
SystemD unit files.
Specifying multiple -q options gives Sidekiq a fallback order for working on
jobs, so for instance -q default -q pull means that when all default jobs
are done, that process will start working on pull jobs.
Make sure that there is at least one process prioritizing every queue,
or else processing that queue could stall entirely!
Because the queues you want to prioritize are default, push, and pull,
it might be sensible to make processes with all the permutations of
default, push, and pull:
default,push,pulldefault,pull,pushpull,default,pushpull,push,default*push,default,pullpush,pull,default*
However, in reality, push is generally much lower volume than the others,
so it makes more sense to drop the number of queues to four, removing the
fourth and final orderings (marked with *).
To do this in Docker, simply copy and paste the sidekiq service definition,
change the name, and add arguments to the invocation.
For instance, we might go from this default definition:
sidekiq:
build: .
image: tootsuite/mastodon:v3.4.6
restart: always
env_file: .env.production
command: bundle exec sidekiq
depends_on:
- db
- redis
networks:
- external_network
- internal_network
volumes:
- ./public/system:/mastodon/public/system
healthcheck:
test: ['CMD-SHELL', "ps aux | grep '[s]idekiq\ 6' || false"]
To these definitions:
sidekiq-mailers:
build: .
image: tootsuite/mastodon:v3.4.6
restart: always
env_file: .env.production
command: bundle exec sidekiq -q mailers -q scheduler
depends_on:
- db
- redis
networks:
- external_network
- internal_network
volumes:
- ./public/system:/mastodon/public/system
healthcheck:
test: ['CMD-SHELL', "ps aux | grep '[s]idekiq\ 6' || false"]
sidekiq-scheduler:
build: .
image: tootsuite/mastodon:v3.4.6
restart: always
env_file: .env.production
command: bundle exec sidekiq -q scheduler
depends_on:
- db
- redis
networks:
- external_network
- internal_network
volumes:
- ./public/system:/mastodon/public/system
healthcheck:
test: ['CMD-SHELL', "ps aux | grep '[s]idekiq\ 6' || false"]
sidekiq-default-push-pull:
build: .
image: tootsuite/mastodon:v3.4.6
restart: always
env_file: .env.production
command: bundle exec sidekiq -q default -q push -q pull
depends_on:
- db
- redis
networks:
- external_network
- internal_network
volumes:
- ./public/system:/mastodon/public/system
healthcheck:
test: ['CMD-SHELL', "ps aux | grep '[s]idekiq\ 6' || false"]
sidekiq-default-pull-push:
build: .
image: tootsuite/mastodon:v3.4.6
restart: always
env_file: .env.production
command: bundle exec sidekiq -q default -q pull -q push
depends_on:
- db
- redis
networks:
- external_network
- internal_network
volumes:
- ./public/system:/mastodon/public/system
healthcheck:
test: ['CMD-SHELL', "ps aux | grep '[s]idekiq\ 6' || false"]
sidekiq-pull-default-push:
build: .
image: tootsuite/mastodon:v3.4.6
restart: always
env_file: .env.production
command: bundle exec sidekiq -q pull -q default -q push
depends_on:
- db
- redis
networks:
- external_network
- internal_network
volumes:
- ./public/system:/mastodon/public/system
healthcheck:
test: ['CMD-SHELL', "ps aux | grep '[s]idekiq\ 6' || false"]
sidekiq-push-default-pull:
build: .
image: tootsuite/mastodon:v3.4.6
restart: always
env_file: .env.production
command: bundle exec sidekiq -q push -q default -q pull
depends_on:
- db
- redis
networks:
- external_network
- internal_network
volumes:
- ./public/system:/mastodon/public/system
healthcheck:
test: ['CMD-SHELL', "ps aux | grep '[s]idekiq\ 6' || false"]
Fully Utilize Your Database
Now that it’s got more to work with,
take note of the max_connections parameter you set for Postgres.
Ideally, those connections would be mostly, but not completely, utilized.
Database contention will slow you down.
The DB_POOL variable controls how many database connections a Ruby on
Rails process will use.
(MAX_THREADS controls this for Puma, the server used in web.)
In Mastodon, the relevant Rails processes are in the
Docker-Compose services web, streaming, and whatever Sidekiq services you’ve
configured.
In docker-compose.yml, you can change these variable by adding a section like
the following to each relevant service:
environment:
- DB_POOL=value
On sidekiq services, also add the -c option to the sidekiq invocation,
with the same value as the DB_POOL variable.
command: bundle exec sidekiq -q default -q push -q pull -c 25
environment:
- DB_POOL=25
In addition, the web service takes a variable called WEB_CONCURRENCY to
control how many processes it runs.
Similarly, streaming has STREAMING_CLUSTER_NUM to control the number
of processes.
The sum of MAX_THREADS times WEB_CONCURRENCY in web,
STREAMING_CLUSTER_NUM times DB_POOL in streaming,
and all the sidekiq DB_POOL variables, must be less than max_connections
in your Postgres config.
If it’s more, you’ll experience database contention.
In the example above, assuming the rest of the configuration is default and you have 200 database connections available, I’d set the following:
web:MAX_THREADS = 10,WEB_CONCURRENCY=3for 30 connectionsstreaming:STREAMING_CLUSTER_NUM = 3,DB_POOL = 15for 45 connectionssidekiq-default-push-pull:DB_POOL = 25,-c 25for 25 connectionssidekiq-default-pull-push:DB_POOL = 25,-c 25for 25 connectionssidekiq-pull-default-push:DB_POOL = 25,-c 25for 25 connectionssidekiq-push-default-pull:DB_POOL = 25,-c 25for 25 connectionssidekiq-push-scheduler:DB_POOL = 5,-c 5for 5 connectionssidekiq-push-mailers:DB_POOL = 5,-c 5for 5 connections
For a sum of 185 connections. This means there will be 15 loose database connections for things like migrations and manually connecting to the database to do queries and maintenance.
Mastodon 4.0
Weirder Earth does not use Mastodon 4.0, but if you do, you will also have to
consider the ingress queue.
Into the Future
These numbers may not work perfectly for you, and you may have to tweak things as workloads change.
There is more work left to do, and we’ll only know if this is successful once the next big wave hits, but it’s definitely better than it was before. We also have not figured out how to monitor the instance for future events, though the top candidate is, of course, Prometheus and Grafana.
Good luck. May your timelines run smoothly and your processes never be OOM killed.
-
Wilfred Chan, “Mastodon gained 70,000 users after Musk’s Twitter takeover. I joined them”, The Guardian (2022 11 02). ↩︎
-
ActivityPub is a W3C Recommendation. See https://activitypub.rocks/ ↩︎
-
I also typo’d
mailersasmailer, which lead to some stalled emails. Don’t do that. ↩︎